AI that does the work.
RAG, agents, LLM integrations — measured, grounded, deployed.
WHAT DO WE BUILD?
Five categories: chatbots, internal agents, RAG, LLM features, ops automations.
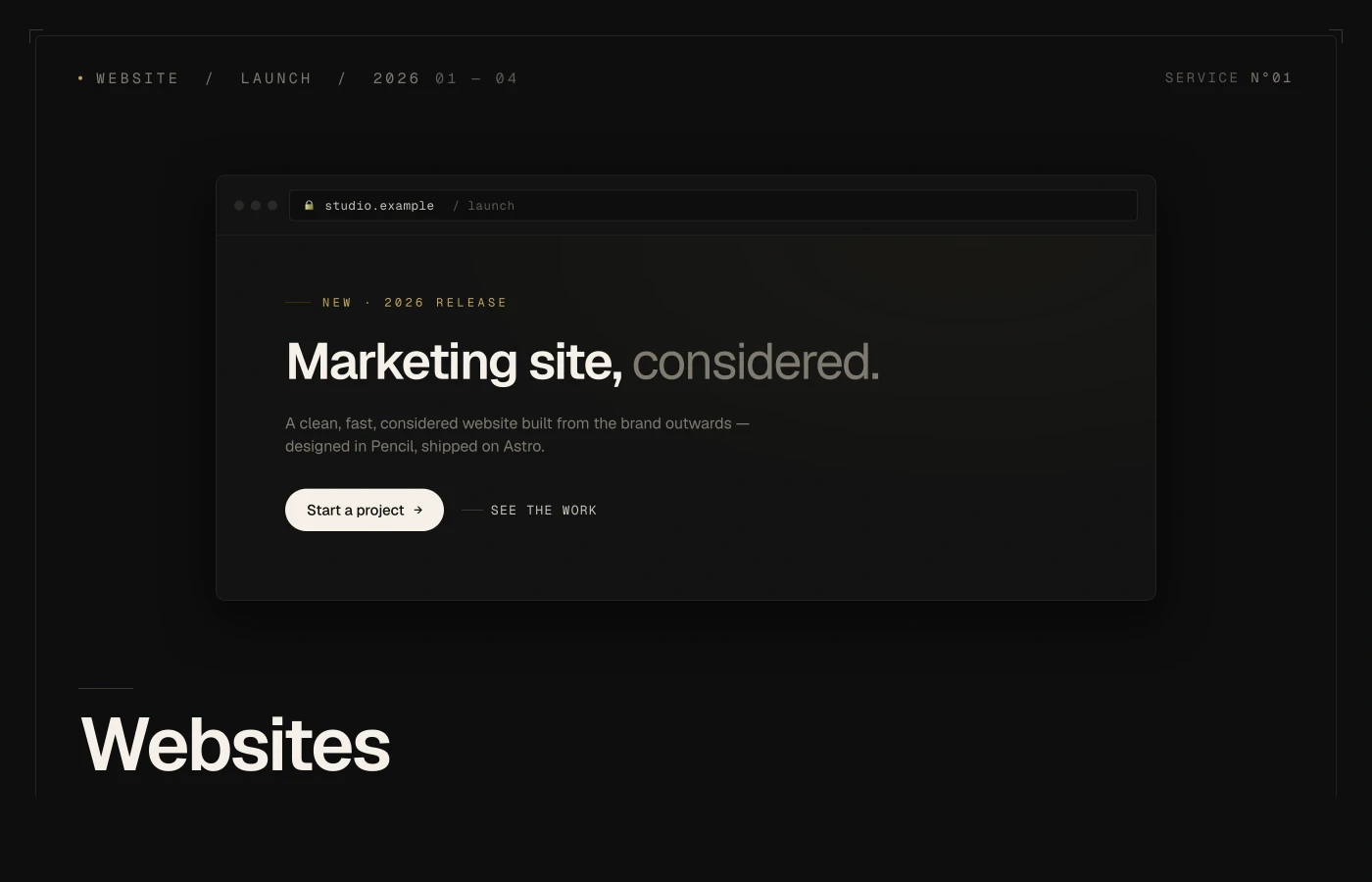
Customer-facing chatbots
Real business logic, not scripted FAQs.
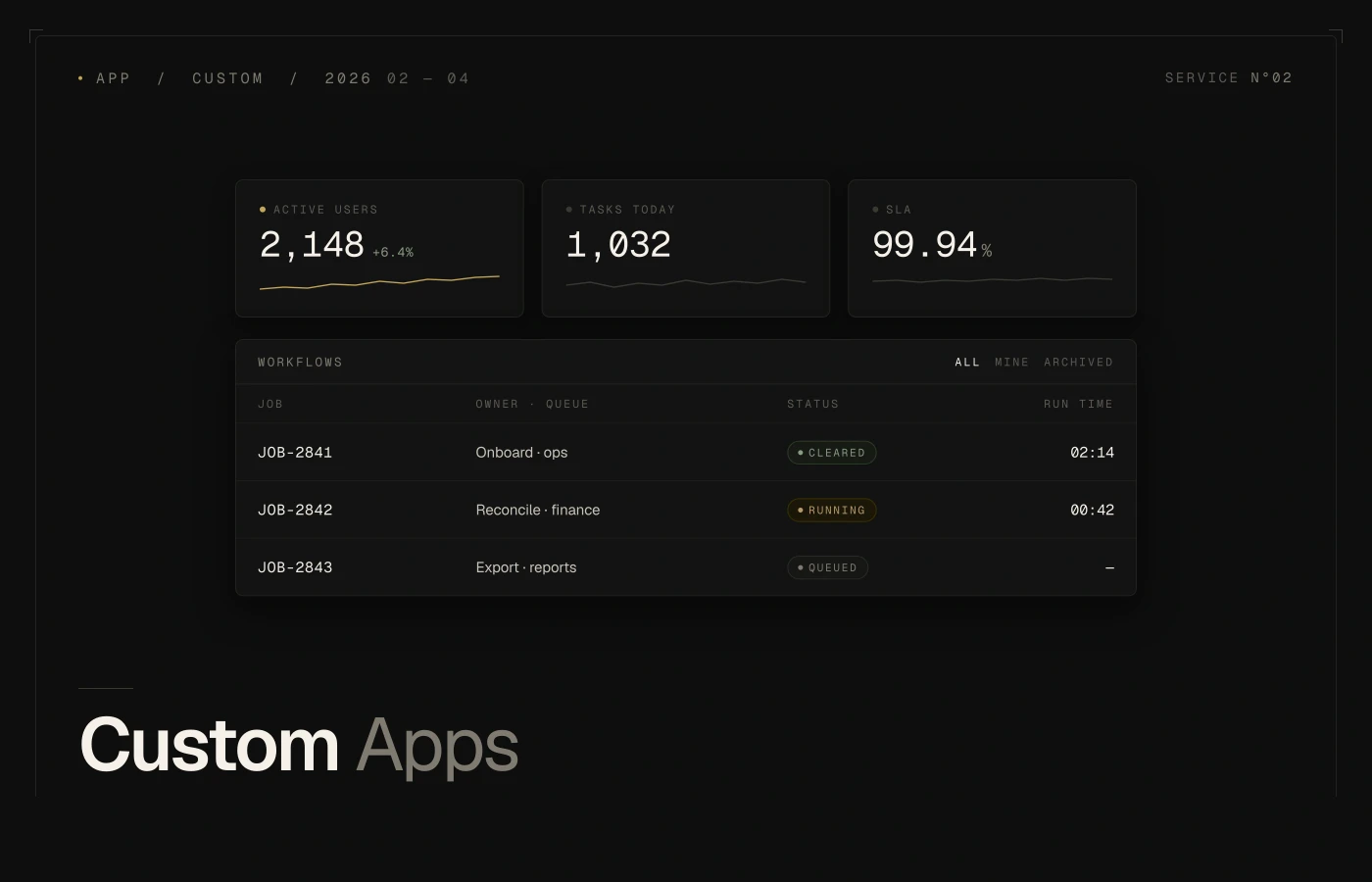
Internal AI agents
Multi-step workflow automation.
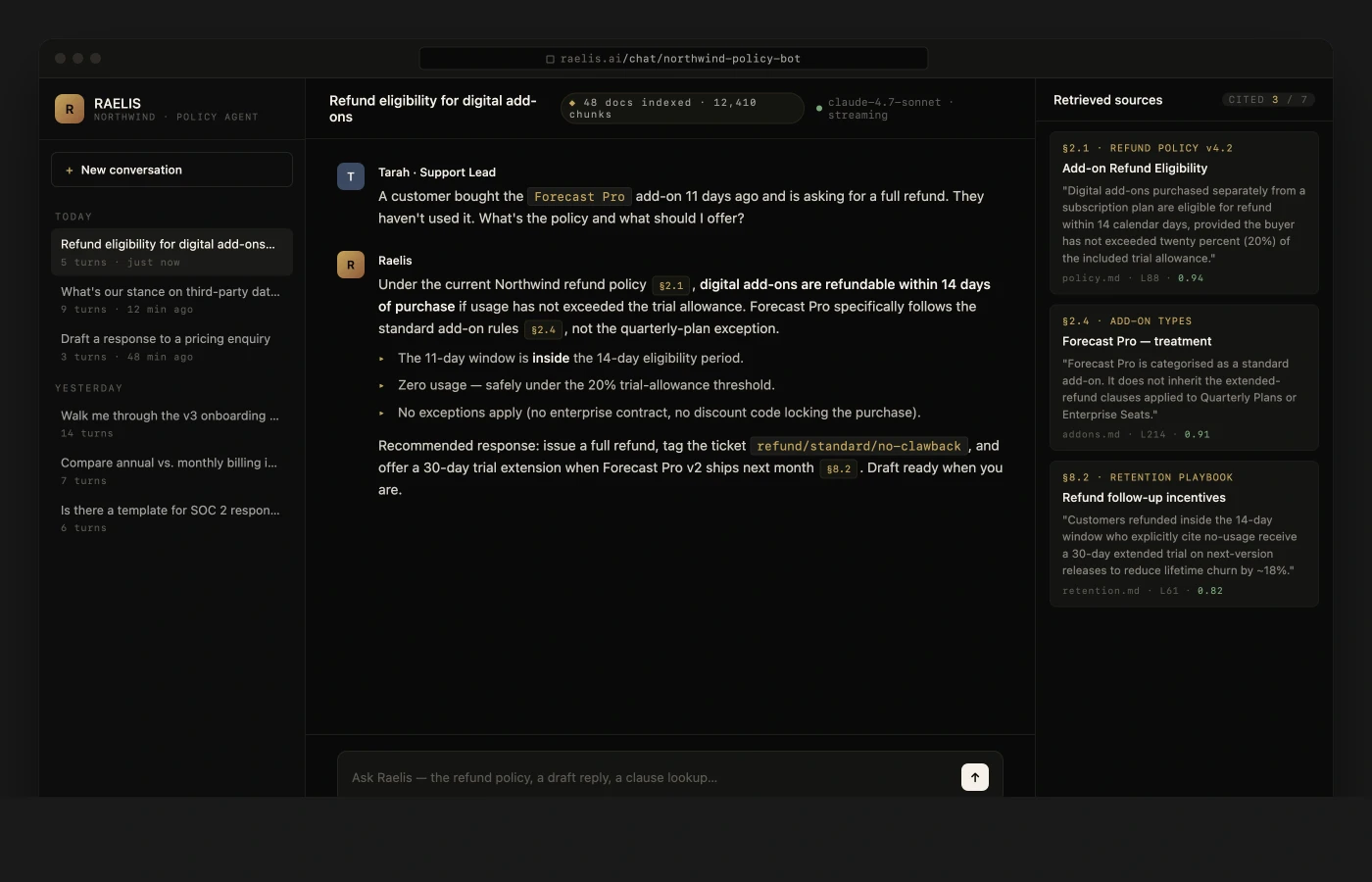
RAG systems
Chat your docs, knowledge base, or product data.
LLM integrations
AI features inside existing products.
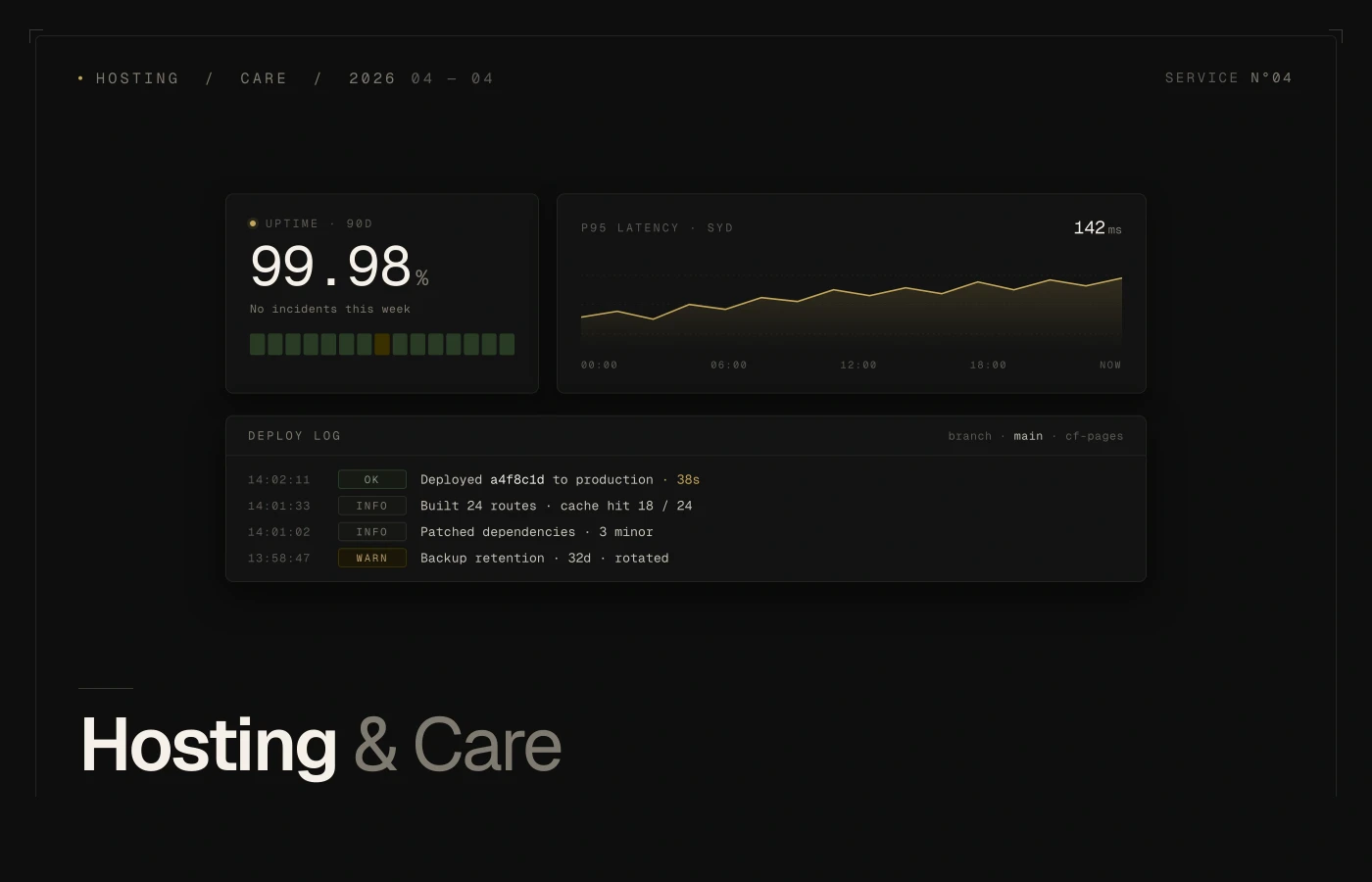
AI-powered automations
Ops workflows that run themselves.
HOW DOES IT WORK?
Pick a model per task. Wire it up. Measure accuracy. No vendor lock-in.
Model selection
Claude, GPT, Gemini — chosen per task, no lock-in.
Retrieval stack
Embeddings, vector DB, hybrid search.
Data handling
Your data stays yours. We document storage, retention, redaction.
Integration patterns
REST, streaming, function-calling, MCP.
Evals & guardrails
Accuracy measured before and after shipping.
Modern AI is shippable today. The difference between a demo and a real system is the wiring: data, evals, guardrails, handoffs. That's what we build.
DREAM IO
FAQ
Which models do you use?
Claude, GPT, Gemini — picked per task. No lock-in.
Is my data used for training?
No. We use APIs from providers that don't train on your data.
Do you fine-tune models?
Almost never. Prompt + RAG gets 90% of real-world wins, faster and cheaper.
How do you measure accuracy?
Evals before shipping; ongoing monitoring after.
How much does it cost to run?
Depends on volume. Token spend and latency modelled upfront.
Timeline?
4–12 weeks, discovery to production.