Market research that answers back.
Retrieval-augmented generation · Build-to-Rent · Sydney
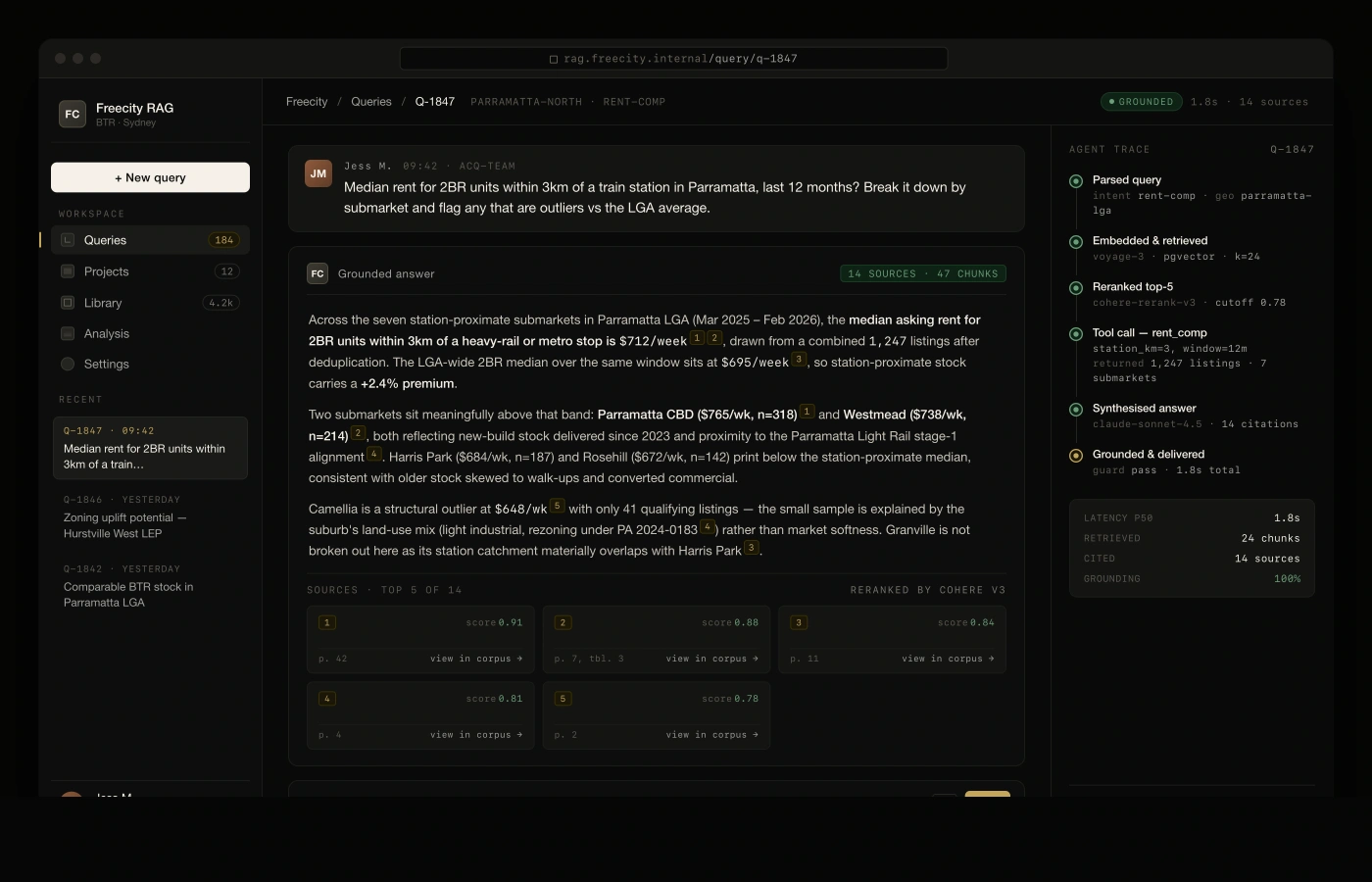
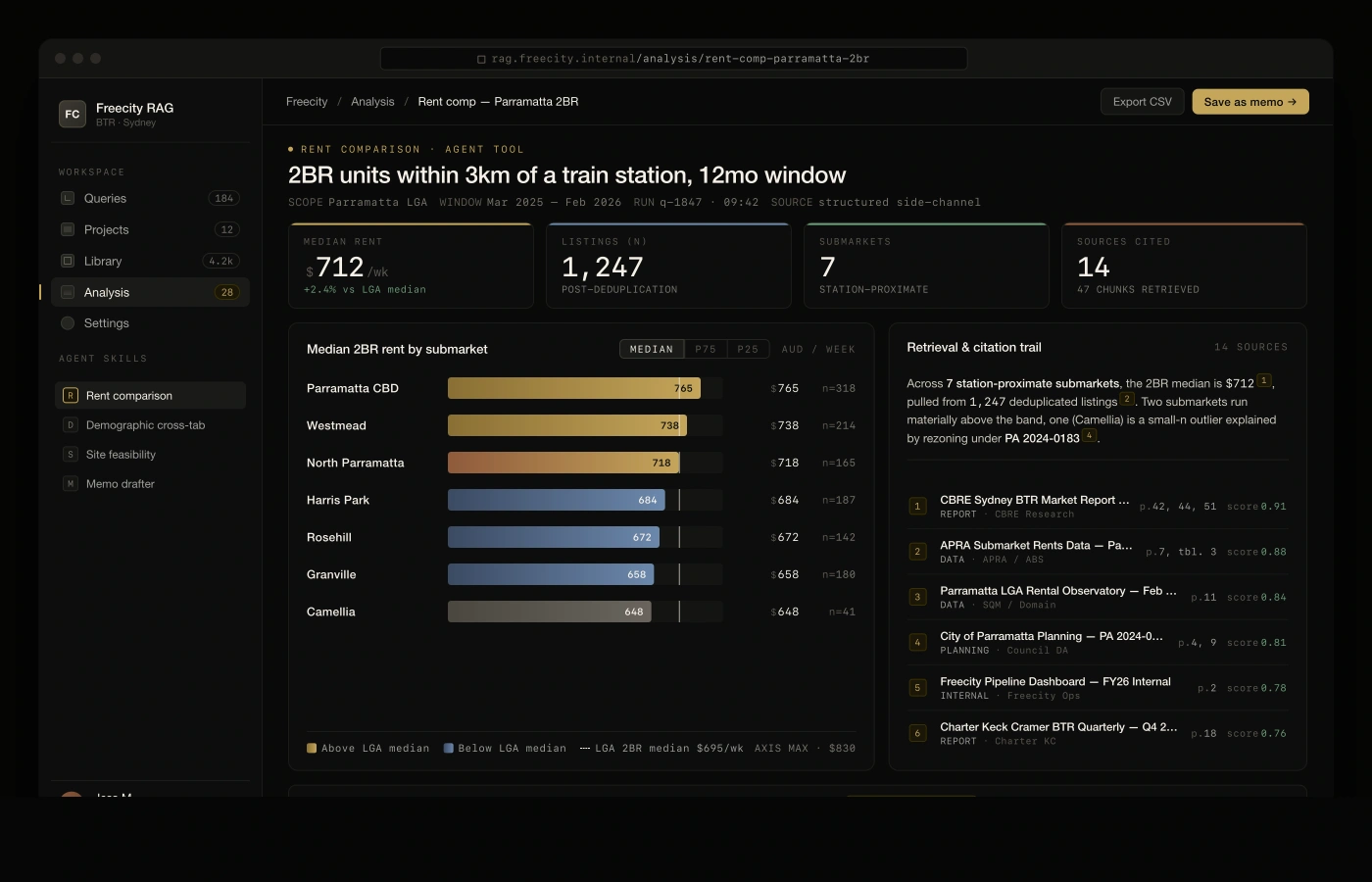
Freecity — a Sydney property developer with a growing Build-to-Rent pipeline — was sitting on years of market reports, rent comps, zoning analyses, demographic studies, and post-mortems. All of it trapped in PDFs and SharePoint folders. We designed and built a retrieval-augmented generation system that ingests the corpus, grounds every answer in the source documents, and lets the acquisitions team interrogate it through a chat interface with agent tools for quantitative analysis.
APPROACH
Market data, trapped in PDFs.
We started with their mess, not a clean corpus.
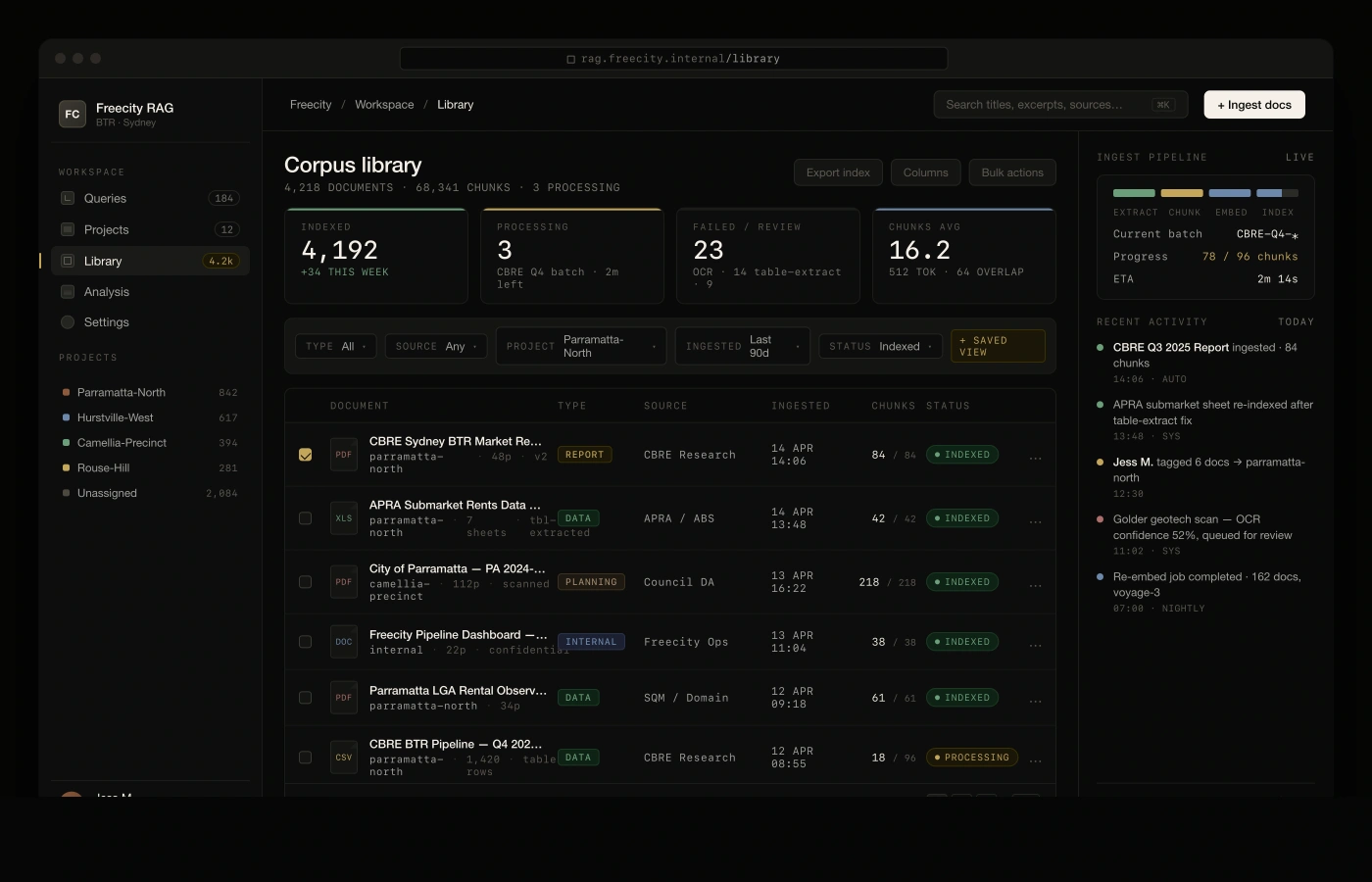
Around 4,200 documents spread across SharePoint, email exports, and analyst laptops. Table-heavy PDFs needed a layout-aware extractor before chunking. 512-token chunks with 64-token overlap, parent-document metadata preserved so every retrieval could walk back to its page.
OUTCOMES
The morning hunt
disappeared.
The system rolled out to the acquisitions team first, then BD and investment. What changed, in order of how the team talked about it:
Roughly 11 hours per analyst per week returned to higher-value work — the morning "hunt for the number" disappeared. Queries that used to mean trawling three shared drives now resolve in one chat turn.
92% on the 80-question eval set at top-5, up from 58% on the first-pass pipeline. Adversarial red-team pass rate locked above 95% before each release.
1.8 seconds p50 from question to first citation on the screen, tool calls included. Fast enough that analysts query mid-meeting instead of taking notes and circling back later.
100% of answers carry page-level source citations — every claim clickable back to the PDF it came from. Ungrounded responses are refused rather than hallucinated.
Full query, retrieval, and tool-call logs with user, timestamp, and document provenance. The answer to "where did that figure come from" is a query, not an archaeology dig.
“It reads the research so we can actually use it.”
Started as a pre-engagement website audit; escalated into an AI system build as the data problem surfaced.
Freecity is a Sydney property developer with an expanding Build-to-Rent book. We began with a website audit, watched the acquisitions team work, and built a retrieval-augmented generation system end-to-end — corpus ingestion, grounding, agent tools, guardrails, and the chat UI — and continue to ship improvements under a care retainer.
ONGOING
Living corpus.
Living system.
The RAG system is a living artifact — the corpus grows each week as new market reports, zoning updates, and project post-mortems land. We ship retrieval and prompt improvements iteratively, expand the agent-tool set in response to analyst asks, and hold the eval and red-team sets as the quality bar. The version live today is meaningfully different from the version six months ago, and it will be different again in six.